


Regardless of fast developments in LLMs, our understanding of how these fashions address longer inputs stays poor.
Mosh Levy, Alon Jacoby, and Yoav Goldberg, from the Bar-Ilan College and Allen Institute for AI, investigated how the efficiency of enormous language fashions (LLMs) varies with modifications within the size of the enter textual content they’re given to course of.
They developed a reasoning framework particularly for this goal, permitting them to dissect the affect of enter size on LLM reasoning in a managed atmosphere.
The questioning framework proposed totally different variations of the identical query, every containing the required data for answering the query, padded with extra, irrelevant textual content of various lengths and kinds.
This permits the isolation of enter size as a variable, making certain that modifications in mannequin efficiency may be attributed on to the size of the enter.
Key findings
Levy, Jacoby, and Goldberg uncovered that LLMs exhibit a noteworthy decline in reasoning efficiency at enter lengths far under what builders assert they will deal with. They documented their findings on this examine.
Decline was constantly noticed throughout all variations of the dataset, indicating a systemic difficulty with dealing with longer inputs quite than an issue tied to particular knowledge samples or mannequin architectures.
Because the researchers describe, “Our findings present a notable degradation in LLMs’ reasoning efficiency at a lot shorter enter lengths than their technical most. We present that the degradation pattern seems in each model of our dataset, though at totally different intensities.”
Furthermore, the examine highlights how conventional metrics like perplexity, generally used to guage LLMs, fail to correlate with the fashions’ efficiency on reasoning duties involving lengthy inputs.
Additional exploration discovered that the degradation in efficiency was not solely depending on the presence of irrelevant data (padding) however was noticed even when such padding consisted of duplicated related data.
Once we hold the 2 core spans collectively and add textual content round them, accuracy already drops. Introducing paragraphs between spans, outcomes drop rather more. The drop happens each when the texts we add are just like the duty texts, and when they’re fully totally different. 3/7 pic.twitter.com/c91l9uzyme
— Mosh Levy (@mosh_levy) February 26, 2024
This means that the problem for LLMs lies in filtering out noise and the inherent processing of longer textual content sequences.
Ignoring directions
One important space of failure mode highlighted within the examine is LLMs’ tendency to disregard directions embedded inside the enter because the enter size will increase.
Fashions would additionally generally generate responses indicating uncertainty or lack of adequate data, corresponding to “There may be not sufficient data within the textual content,” regardless of all the required data.
Total, LLMs appear to constantly wrestle to prioritize and give attention to key data items, together with direct directions, as enter size grows.
Exhibiting biases in responses
One other notable difficulty was elevated biases within the fashions’ responses as inputs turned longer.
Particularly, LLMs have been biased in direction of answering “False” as enter size elevated. This bias signifies a skew in chance estimation or decision-making processes inside the mannequin, probably as a defensive mechanism in response to elevated uncertainty as a result of longer enter lengths.
The inclination to favor “False” responses might additionally mirror an underlying imbalance within the coaching knowledge or an artifact of the fashions’ coaching course of, the place unfavourable responses could also be overrepresented or related to contexts of uncertainty and ambiguity.
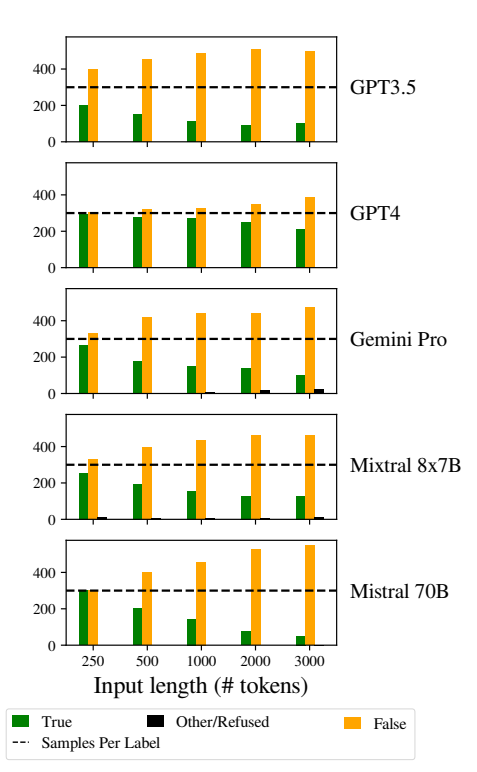
This bias impacts the accuracy of the fashions’ outputs and raises issues concerning the reliability and equity of LLMs in purposes requiring nuanced understanding and impartiality.
Implementing sturdy bias detection and mitigation methods throughout mannequin coaching and fine-tuning phases is crucial to scale back unwarranted biases in mannequin responses.
Ensuring that coaching datasets are various, balanced, and consultant of a variety of eventualities may assist decrease biases and enhance mannequin generalization.
This contributes to different latest research that equally spotlight basic points in how LLMs work, thus resulting in a state of affairs the place that ‘technical debt’ might threaten mannequin performance and integrity over time.

![Her Universe Fashion Show Returns to Showcase Geek Couture at San Diego Comic-Con 2024 [UPDATE July 8]](https://i1.wp.com/sdccblog.com/wp-content/uploads/2018/08/BETH3325w.jpg?w=120&resize=120,86)



{kind=link}