


Google DeepMind researchers developed NATURAL PLAN, a benchmark for evaluating the potential of LLMs to plan real-world duties primarily based on pure language prompts.
The subsequent evolution of AI is to have it depart the confines of a chat platform and tackle agentic roles to finish duties throughout platforms on our behalf. However that’s more durable than it sounds.
Planning duties like scheduling a gathering or compiling a vacation itinerary might sound easy for us. People are good at reasoning via a number of steps and predicting whether or not a plan of action will accomplish the specified goal or not.
You would possibly discover that simple, however even the very best AI fashions wrestle with planning. May we benchmark them to see which LLM is finest at planning?
The NATURAL PLAN benchmark checks LLMs on 3 planning duties:
- Journey planning – Planning a visit itinerary beneath flight and vacation spot constraints
- Assembly planning – Scheduling conferences with a number of mates in numerous areas
- Calendar scheduling – Scheduling work conferences between a number of folks given present schedules and varied constraints
The experiment started with few-shot prompting the place the fashions had been supplied with 5 examples of prompts and corresponding appropriate solutions. They had been then prompted with planning prompts of various problem.
Right here’s an instance of a immediate and answer offered for instance to the fashions:
Outcomes
The researchers examined GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, and Gemini 1.5 Professional, none of which carried out very effectively on these checks.
The outcomes will need to have gone down effectively within the DeepMind workplace although as Gemini 1.5 Professional got here out on high.

As anticipated, the outcomes bought exponentially worse with extra advanced prompts the place the variety of folks or cities was elevated. For instance, have a look at how rapidly the accuracy suffered as extra folks had been added to the assembly planning take a look at.
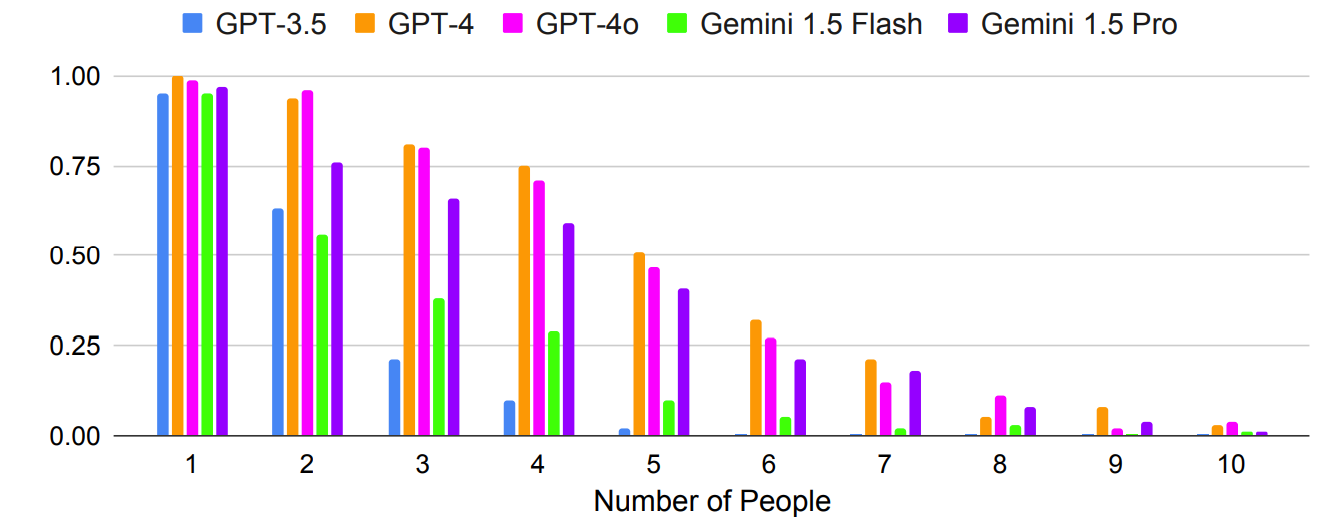
May multi-shot prompting lead to improved accuracy? The outcomes of the analysis point out that it may well, however provided that the mannequin has a big sufficient context window.
Gemini 1.5 Professional’s bigger context window permits it to leverage extra in-context examples than the GPT fashions.
The researchers discovered that in Journey Planning, rising the variety of pictures from 1 to 800 improves the accuracy of Gemini Professional 1.5 from 2.7% to 39.9%.
The paper famous, “These outcomes present the promise of in-context planning the place the long-context capabilities allow LLMs to leverage additional context to enhance Planning.”
An odd consequence was that GPT-4o was actually dangerous at Journey Planning. The researchers discovered that it struggled “to know and respect the flight connectivity and journey date constraints.”
One other unusual consequence was that self-correction led to a major mannequin efficiency drop throughout all fashions. When the fashions had been prompted to test their work and make corrections they made extra errors.
Curiously, the stronger fashions, equivalent to GPT-4 and Gemini 1.5 Professional, suffered larger losses than GPT-3.5 when self-correcting.
Agentic AI is an thrilling prospect and we’re already seeing some sensible use circumstances in Microsoft Copilot brokers.
However the outcomes of the NATURAL PLAN benchmark checks present that we’ve bought some option to go earlier than AI can deal with extra advanced planning.
The DeepMind researchers concluded that “NATURAL PLAN may be very onerous for state-of-the-art fashions to unravel.”
It appears AI gained’t be changing journey brokers and private assistants fairly but.





{kind=link}